Auto-Inject Prompt Caching Checkpoints
Reduce costs by up to 90% by using LiteLLM to auto-inject prompt caching checkpoints.
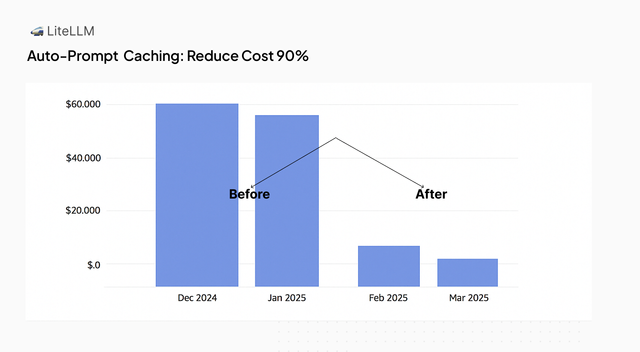
How it works
LiteLLM can automatically inject prompt caching checkpoints into your requests to LLM providers. This allows:
- Cost Reduction: Long, static parts of your prompts can be cached to avoid repeated processing
- No need to modify your application code: You can configure the auto-caching behavior in the LiteLLM UI or in the
litellm config.yamlfile.
Configuration
You need to specify cache_control_injection_points in your model configuration. This tells LiteLLM:
- Where to add the caching directive (
location) - Which message to target (
role)
LiteLLM will then automatically add a cache_control directive to the specified messages in your requests:
"cache_control": {
"type": "ephemeral"
}
Usage Example
In this example, we'll configure caching for system messages by adding the directive to all messages with role: system.
- litellm config.yaml
- LiteLLM UI
model_list:
- model_name: anthropic-auto-inject-cache-system-message
litellm_params:
model: anthropic/claude-3-5-sonnet-20240620
api_key: os.environ/ANTHROPIC_API_KEY
cache_control_injection_points:
- location: message
role: system
On the LiteLLM UI, you can specify the cache_control_injection_points in the Advanced Settings tab when adding a model.
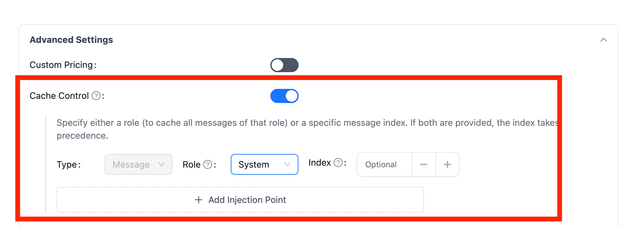
Detailed Example
1. Original Request to LiteLLM
In this example, we have a very long, static system message and a varying user message. It's efficient to cache the system message since it rarely changes.
{
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant. This is a set of very long instructions that you will follow. Here is a legal document that you will use to answer the user's question."
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the main topic of this legal document?"
}
]
}
]
}
2. LiteLLM's Modified Request
LiteLLM auto-injects the caching directive into the system message based on our configuration:
{
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant. This is a set of very long instructions that you will follow. Here is a legal document that you will use to answer the user's question.",
"cache_control": {"type": "ephemeral"}
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the main topic of this legal document?"
}
]
}
]
}
When the model provider processes this request, it will recognize the caching directive and only process the system message once, caching it for subsequent requests.